Statistique : Tester l'association de variables
 Cette grande leçon présente, sous l'angle de la statistique inférentielle, les principales méthodes pour tester l'existence d'une association entre variables : corrélations de variables numériques (r
de Pearson) ordinales (
Cette grande leçon présente, sous l'angle de la statistique inférentielle, les principales méthodes pour tester l'existence d'une association entre variables : corrélations de variables numériques (r
de Pearson) ordinales ( de Spearman,
de Spearman,  de Kendal), ou nominales (
de Kendal), ou nominales ( et
et  ). Après un rappel de la régression linéaire simple, on introduit la corrélation partielle. Finalement, cinq articles sont consacrés à la corrélation multiple.
). Après un rappel de la régression linéaire simple, on introduit la corrélation partielle. Finalement, cinq articles sont consacrés à la corrélation multiple.
8. Régression linéaire : Évaluer la qualité de la relation
8.2. Normalité globale des résidus
Normalité : Si le modèle est idéalement bon, alors les écarts que l’on constate entre les valeurs prédites et les valeurs observées (les résidus donc) sont entièrement imputables à des erreurs de mesure. De ce fait, les résidus doivent posséder les propriétés classiques d’une distribution normale : courbe « en cloche », symétrique autour de la valeur prédite, avec un aplatissement régulier des extrémités. En cas de violation de cette assomption, les tests de signification risquent d’être biaisés.
La première chose est de vérifier si, globalement, les résidus sont bien normalement distribués.
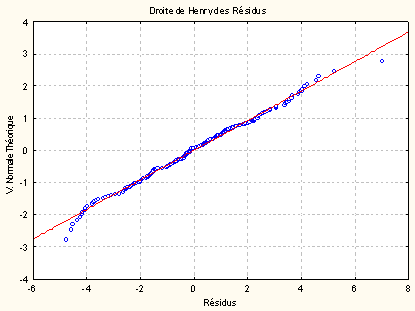
Sous Statistica, on peut par exemple obtenir la « droite de Henry » qui met en relation les valeurs observées des résidus (abscisses) avec des valeurs z construites sous l’hypothèse que la distribution des résidus est normale. Idéalement, on doit avoir l’identité, c'est-à-dire que tous les points du graphe doivent être situés sur la droite en rouge. Ici, le résultat est assez satisfaisant, encore qu’un très léger biais apparaît aux valeurs extrêmes.
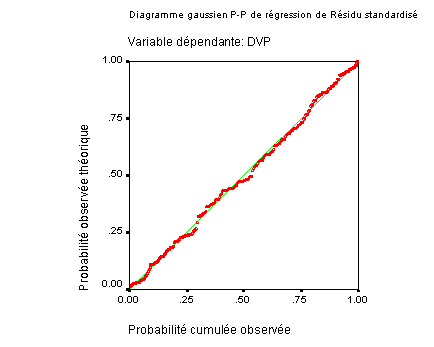
Sous SPSS, on peut demander un « diagramme P-P ». Le principe, assez similaire à celui de la droite de Henry utilisée dans Statistica, est de construire un diagramme mettant en relation la probabilité cumulée d’apparition d’une valeur avec sa probabilité théorique.
Si vous avez des doutes sur la normalité de la distribution des résidus, une stratégie qui permet d’obtenir des informations plus détaillées sur la normalité des résidus consiste à commencer par enregistrer ceux-ci comme de nouvelles variables (option disponible sous SPSS comme sous Statistica), puis à appliquer les procédures générales de test de la normalité d’une variable.
Couleur de fond
Police
Taille de police
Couleur de texte
Crénage de la police
Visibilité de l’image
Espacement des lettres
Hauteur de ligne
Surbrillance de lien