Statistique : Tester l'association de variables
 Cette grande leçon présente, sous l'angle de la statistique inférentielle, les principales méthodes pour tester l'existence d'une association entre variables : corrélations de variables numériques (r
de Pearson) ordinales (
Cette grande leçon présente, sous l'angle de la statistique inférentielle, les principales méthodes pour tester l'existence d'une association entre variables : corrélations de variables numériques (r
de Pearson) ordinales ( de Spearman,
de Spearman,  de Kendal), ou nominales (
de Kendal), ou nominales ( et
et  ). Après un rappel de la régression linéaire simple, on introduit la corrélation partielle. Finalement, cinq articles sont consacrés à la corrélation multiple.
). Après un rappel de la régression linéaire simple, on introduit la corrélation partielle. Finalement, cinq articles sont consacrés à la corrélation multiple.
7. Régression linéaire multiple : Ordre d'introduction des variables
7.1. Régression linéaire multiple : Ordre d'introduction des variables
1. Problématique de l'ordre d'introduction des variables
1.1. Retour sur la notion de multicolinéarité
L’existence d’un certain niveau de redondance entre les VIs pose la question de l’ordre dans lequel la contribution des différentes VIs sera analysée. Par exemple, soient 3 VIs, VI1, VI2 et VI3, ici en bleu, en jaune et en rouge respectivement. Le diagramme de Venn suivant montre la structure de la variance totale, avec des éléments de variance propre à chaque VI (zones en rouge, bleu et jaune) et des éléments de variance partagée (intersections, de couleurs mixées).
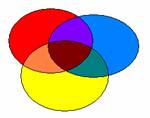
Toutes les méthodes de régression linéaire savent attribuer à chaque VI la variance qui lui est propre. Elles diffèrent sur la façon de répartir la variance partagée.
Le choix de la méthode d’introduction est d’importance majeure s’il s’agit d’évaluer la contribution relative des différentes Vis ou si l’on est en présence d’une forte colinéarité des VIs.
1.2. La Méthode Standard : Introduction Simultanée
Elle consiste à introduire toutes les variables en même temps dans l’analyse, mais à n’imputer à aucune variable en particulier la part de variance partagée. On n’impute à une variable que la part de variance qui lui est propre (les zones colorées dans le diagramme suivant).
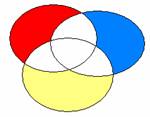
La part de variance partagée (régions en blanc) n’est pas totalement perdue : on la retrouve dans le calcul global de la variance expliquée par le modèle (le R² global).
1.3. Principe des Méthodes Hiérarchiques
Elles consistent pour le chercheur à déterminer un classement de priorité parmi les prédicteurs qu’il est potentiellement possible d’entrer dans l’analyse. Idéalement, ce classement sera fondé sur des bases théoriques.
On peut avoir plusieurs niveaux hiérarchiques, avec un bloc de variables à chaque niveau.
Admettons pour simplifier qu’il n’y ait qu’une VI par bloc. La variable prioritaire se taille la part du lion : elle se voit attribuer toute la variance partagée avec les variables de rang inférieur, lesquelles ne gardent que la part de variance qui leur est propre. Admettons, par exemple, que le chercheur ait des raisons théoriques de penser que la VI bleue soit plus importante que les autres, puis que la rouge soit plus importante que la jaune. Il va donc entrer d’abord la bleue dans le premier bloc. Elle recevra toute la variance qui la concerne, y compris ce qu’elle partage avec la rouge et la jaune. Puis la rouge, dans le deuxième bloc, recevra ce qui la concerne, y compris ce qu’elle partage avec la jaune, mais moins ce qui a déjà été attribué à la bleue. Enfin la jaune, dans le troisième bloc, ne recevra que ce qui la concerne en propre
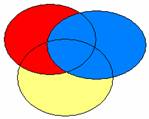
L'intérêt de cette approche est que la somme des variances expliquées par chaque VI est égale à la variance expliquée totale. Toutefois, l'attribution de la variable partagée à l'une des variables plutôt qu'aux autres est fondamentalement arbitraire (le choix d'attribuer en priorité la variance partagée à la variable qui explique le plus de variance propre est un choix tout aussi arbitraire qu'un autre)... De ce point de vue, les autres méthodes produisent une attribution différente, mais pas mieux fondée.
1.4. Principe des Méthodes Statistiques (ou « séquentielles »)
Elles consistent à introduire ou à retirer les variables une par une, comme dans le cas des variables hiérarchiques. Ce qui caractérise les méthodes statistiques, c’est que la hiérarchie est déterminée par le logiciel, sur des bases statistiques uniquement.
Ces méthodes sont très discutées car, lorsque plusieurs VI partagent une part substantielle de variance, elles conduisent à des résultats instables. En outre, leur sensibilité à des aspects mathématiques ne reposant sur aucune justification théorique propre au domaine étudié est aussi discutable.
Il existe plusieurs méthodes d’introduction séquentielle que nous allons détailler dans les sections suivantes de ce chapitre. Il existe aussi d’autres méthodes que nous laisserons de côté ici(e.g., la régression dite « ridge »).
1.5. Combinaison des types de Méthodes
Des logiciels comme SPSS permettent de combiner les différentes méthodes.
Par exemple, si le chercheur répartir 12 VIs entre 3 blocs hiérarchiques de 4 VIs chacun, il peut déterminer la méthode d’introduction qui sera utilisée à l’intérieur de chaque bloc.
Par exemple,l’introduction traitement des VI du bloc 1 peut être réalisée la méthode standard tandis qu’ensuite le traitement du bloc 2 sera réalisé par une méthode statistique.
Pour une comparaison des avantages et inconvénients de chaque méthode, voir par exemple Tabachnick et Fidell (1996).
Couleur de fond
Police
Taille de police
Couleur de texte