La statistique d’écart studentisée
Objectifs. Introduire une statistique qui est rarement utilisée pour elle-même, mais prend part à de nombreux tests post-hoc dans les ANOVA.
Prérequis. Test t de Student ; ANOVA
Résumé. La statistique d'écart studentisée q s'obtient en procédant à une sorte de test t portant sur les deux valeurs les plus extrêmes (haute et basse) d'un ensemble de moyennes. Une table des valeurs critiques de q en fonction du nombre de comparaisons impliquées dans l'ANOVA globale et le nombre de degrés de libertés de la comparaison est fournie.
1. Utilisation
La statistique d'écart studentisée ("studentized range" en anglais) notée q, est une fonction utilisée pour calculer différents tests post-hoc dans l'analyse de variance. Dans ce type de tests, plusieurs comparaisons de moyennes sont réalisées et l'on doit corriger le calcul de la valeur de significativité d'un test afin que l'erreur de l'ensemble des comparaisons ne dépasse pas le seuil qu'on se donne comme convention (généralement 5%, parfois 1% ou même moins, mais c'est rare pour les tests post-hoc).
La valeur q possède une distribution d’échantillonnage à partir de laquelle on peut construire des tables donnant ses valeurs critiques, c’est-à-dire les valeurs de q qu’il faut dépasser pour avoir une différence significative (voir par exemple la table de q que nous avons fournie en bas de cette page ou l'Annexe q de Howell). Les valeurs critiques de q, c'est-à-dire les valeurs que q doit dépasser pour être considéré comme significatif, dépendent de deux paramètres, le nombre r de groupes intervenant dans la comparaison globale (par exemple s’il y a 4 groupes, r =4), et le nombre de degrés de liberté de l'erreur de la comparaison globale (généralement N-k où N est le nombre total de sujets et k le nombre de groupes). C'est pourquoi on peut aussi la noter aussi qr,ddl en signalant ainsi directement les deux paramètres intéressants, la valeur de r et celle du nombre de degrés de libertés.
Pourquoi doit-on utiliser ce paramètre r ? Tout simplement parce que plus il y a de groupes, plus l’écart entre la moyenne la plus basse et la plus haute risque d’être élevée et donc si H0 globale est vraie, plus on risque de commettre une erreur de type I.
2. Calcul de q
On commence par ranger les moyennes des r différents groupes par ordre croissant de leurs valeurs moyennes, M1 , M2 ,..., Mr . La valeur q s’obtient très facilement à partir de la valeur t de comparaison des moyennes des deux groupes les plus extrêmes dans le classement, à savoir celui correspondant à M1 , la moyenne la plus faible et celui correspondant à Mr , la moyenne la plus forte. En effet, on a
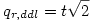
2.1. Cas avec variances homogènes
Vous pouvez aussi calculer q directement à partir de ces deux moyennes, M1 et Mr , sans passer par le calcul de t , en appliquant la formule :
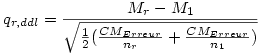
Le CMErreur s'obtient directement dans le tableau d'ANOVA. Bien sûr si les effectifs sont égaux, la formule précédente se simplifie puisqu'alors nr = n1.
2.2. Cas avec variances hétérogènes
Lorsque les échantillons sont de taille inégales mais les variances homogènes, Games et Howell (voir Howell, p. 384) ont proposé de calculer les choses séparément pour chaque paire de moyennes Mi , Mj :
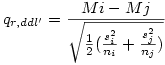
Le lecteur aura noté que la formule fait référence à ddl' et non plus simplement ddl. On compare donc q avec la valeur critique obtenue dans la table avec les paramètres r et le nombre de degrés de liberté ddl'. La valeur de ddl' à utiliser s'obtient par la formule
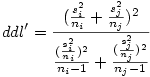
Couleur de fond
Police
Taille de police
Couleur de texte
Crénage de la police
Visibilité de l’image
Espacement des lettres
Hauteur de ligne
Surbrillance de lien
Alignement du texte
Largeur de paragraphe